
[머신러닝] 머신러닝의 개요
Updated:
Intro
2019년 2학기 인공지능 과목을 수강하였습니다. 한 학기만 수강하고 인공지능 공부를 끝내자니 아쉽고 많이 부족한것 같아서 이번 2020년 동계 방학에 인공지능의 한 개념인 머신 러닝에 대해 공부를 해보고자 합니다.
4차 산업혁명의 핵심기술인 사물인터넷(IoT), 클라우드(Cloud), 빅데이터(Big Data), 인공지능(AI, Artificial Intelligence)의 발전이 우리의 생활을 빠르게 발전시키고 있습니다. 그 중에서도 인공지능에 대해 다뤄보고자 합니다. 인공지능 기술이 혁명적으로 발전할 수 있었던 데에는 사람이 규칙을 찾아 프로그래밍을 하는 전통적인 인공지능 프로그래밍 방식 대신, 많은 데이터와 학습을 통해 규칙을 스스로 찾아내는 머신 러닝(Machine Learning)이 새로운 프로그래밍의 패러다임으로 변화하였기 때문입니다.
인공지능이 크게 이슈화 된것은 2016년에 있었던 구글 딥마인드의 알파고와 이세돌 9단의 바둑 대국이었습니다. 이 대국에서 알파고의 승리로 대중들은 어떻게 기계가 사람을 이겼는가에 주목하기 시작했고, 그 중심에는 인공지능(AI), 머신 러닝(Machine Learning), 딥러닝(Deep Learning)이 있다는 것을 알게 되었습니다.
이번 글을 통해 인공지능(AI)의 핵심 개념인 머신 러닝의 개요에 대해 알아보겠습니다.
Machine Learning 이란?
머신 러닝(Machine Learning)은 기계 학습 이라고도 할 수 있습니다. 인공지능의 한 분야로, 기계가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야 입니다. 기계가 학습을 하기 위해서는 반드시 학습 할 수 있는 데이터 가 필요합니다. 머신 러닝은 금융 서비스, 의료 서비스, 마케팅 및 영업, 운송 등 다양한 분야에서 적극적으로 활용 중 입니다.
인공지능 > 머신러닝 > 딥러닝
다양한 분야에서 인공지능, 머신러닝, 딥러닝 등의 기술들이 응용되고 있습니다. 그래서 그런지 요즘 미디어에서는 인공지능, 머신러닝, 딥러닝과 같은 용어들이 혼용되어 사용되고 있습니다.
아래는 인공지능과 머신러닝, 딥러닝의 관계를 도식화 한 그림입니다. 그림을 보면 세 개념들의 차이를 확연하게 느낄 수 있을것입니다.

-
인공지능(AI, Artificial Intelligence)
인공지능은 인간의 지능이 갖고 있는 기능을 갖춘 컴퓨터 시스템이며, 인간의 지능을 기계 등에 인공적으로 시연(구현)한 가장 큰 범주에 해당합니다. 일반적으로 범용 컴퓨터에 적용한다고 가정합니다. -
머신러닝(Machine Learning)
기계 학습 또는 머신 러닝은 인공지능의 한 분야로, 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야를 말합니다. -
딥 러닝(Deep Learning)
심층 학습 또는 딥 러닝은 여러 비선형 변환기법의 조합을 통해 높은 수준의 추상화를 시도하는 기계 학습 알고리즘의 집합으로 정의 됩니다. 큰 틀에서 사람의 사고방식을 컴퓨터에게 가르치는 기계학습의 한 분야라고 이야기할 수 있습니다. 딥 러닝은 특징 추출부터 패턴까지 모든 과정을 사람의 개입 없이 심층인공신경망을 토대로 학습방식을 구현하는 기술입니다.
머신러닝 vs 딥러닝
아래 그림은 머신러닝과 딥러닝의 차이에 대해 설명해주는 그림입니다.
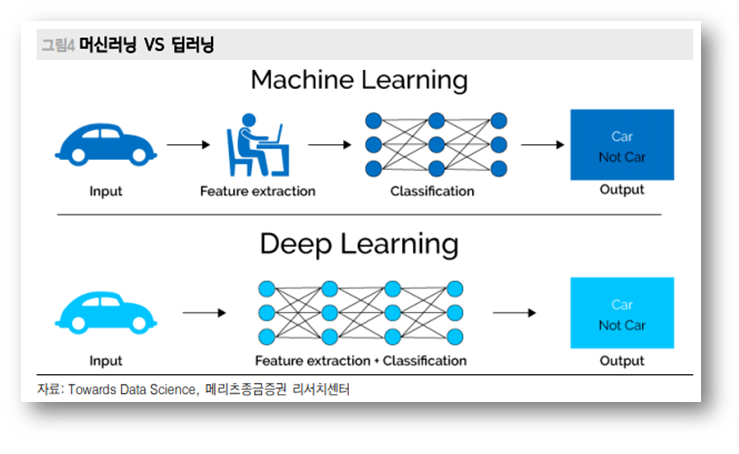
- 머신러닝은 인간이 데이터에 대한 결과 값을 미리 알려주어야 하고 목표치에 가까운 결과 값의 특징을 미리 정의해야 합니다.
- 반면에 딥러닝은 인간의 신경망인 뉴런의 작동 원리를 모방한 인공 신경망을 이용하여 복잡하고 방대한 데이터로부터 결과값을 추출하는 원리로 작동합니다.
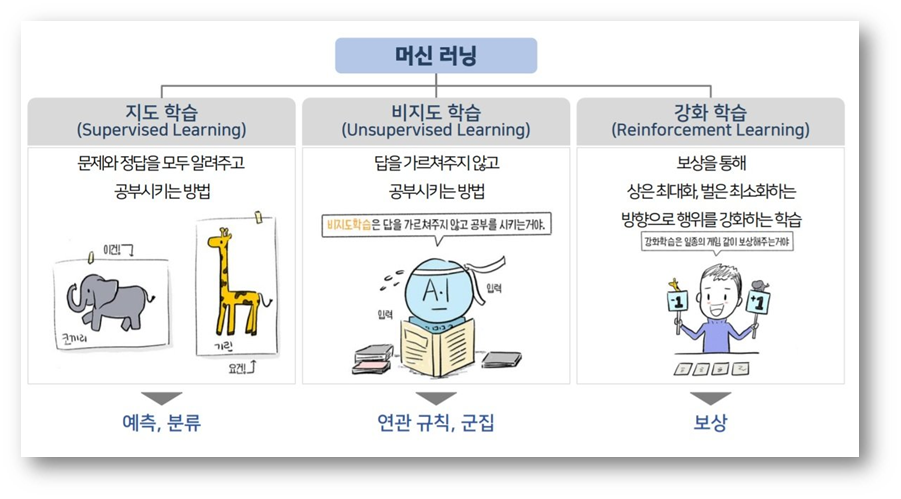
머신러닝 알고리즘의 유형
가장 많이 사용되는 머신러닝 유형에 대해 알아보겠습니다.
-
지도학습(Supervised learning)
지도 학습 알고리즘은 한 세트의 사례들을(examples) 기반으로 예측을 수행합니다. 예를 들어, 과거 매출 이력을 이용해 미래 가격을 추산할 수 있습니다. 지도학습에는 기존에 이미 분류된 학습용 데이터(labeled trainig data)로 구성된 입력 변수와 원하는 출력 변수가 수반됩니다. 알고리즘을 이용해 학습용 데이터를 분석함으로써 입력 변수를 출력 변수와 매핑시키는 함수를 찾을 수 있습니다. 이렇게 추론된 함수는 학습용 데이터로부터 일반화(generalizing)를 통해 알려지지 않은 새로운 사례들을 매핑하고, 눈에 보이지 않는 상황 속에서 결과를 예측 합니다.지도 학습은 학습 결과를 바탕으로 미래의 무엇을 예측하냐에 따라 분류, 회기, 예측으로 구분할 수 있습니다.
-
분류(Classification):
데이터가 범주형 변수를 예측하기 위해 사용될 때 지도학습을 ‘분류’라고 하기도 합니다. 이미지에 강아지나 고양이와 같은 레이블을 할당하는 경우가 해당됩니다. 레이블이 두 개인 경우를 이진 분류(binary classification)라고 부르며, 범주가 두 개 이상인 경우는 다중 클래스 분류(multi-class classification)라고 부릅니다. -
회귀(Regression):
연속 값을 예측할 때 문제는 회귀 문제가 됩니다. 트레이닝 데이터를 이용하여 연속적인 값을 예측하는 것을 말합니다. -
예측(Forecasting):
과거 및 현재 데이터를 기반으로 미래를 예측하는 과정입니다. 예측은 동향(trends)을 분석하기 위해 가장 많이 사용됩니다. 예를 들어 올해와 전년도 매출을 기반으로 내녀도 매출을 추산하는 과정입니다.
-
-
비지도학습(Unsupervised learning)
비지도 학습은 수행할 때 기계는 미분류 데이터만을 제공 받습니다. 그리고 기계는 클러스터링 구조(clustering structure), 저차원 다양체(low-dimensional manifold), 희소 트리 및 그래프(a sparse tree and graph) 등과 같은 데이터의 기저를 이루는 고유 패턴을 발견하도록 설정됩니다.-
클러스터링(Clustering):
특정 기준에 따라 유사한 데이터 사례들을 하나의 세트로 그룹화합니다. 이 과정은 종종 전체 데이터 세트를 여러 글부으로 분류하기 위해 사용됩니다. 사용자는 고유한 패턴을 찾기 위해 개별 그룹 차원에서 분석을 수행할 수 있습니다. -
차원 축소(Dimension Reduction):
고려 중인 변수의 개수를 줄이는 작업입니다. 많은 애플리케이션에서 원시 데이터(raw data)는 아주 높은 차원의 특징을 지닙니다. 이때 일부 특징들은 중복되거나 작업과 아무 관련이 없습니다. 따라서 차원수를 줄이면 관계를 도출하기 용이해집니다.
-
-
강화학습(Reinforcement learning)
강화 학습은 환경으로부터의 피드백을 기반으로 행위자(agent)의 행동을 분석하고 최적화 합니다. 기계는 어떤 액션을 취해야 할지 듣기 보다는 최고의 보상을 산출하는 액션을 발견하기 위해 서로 다른 시나리오를 시도합니다. 시행 착오(Trial-and-error)와 지연 보상(delayed reward)은 다른 기법과 구별되는 강화 학습만의 특징입니다.
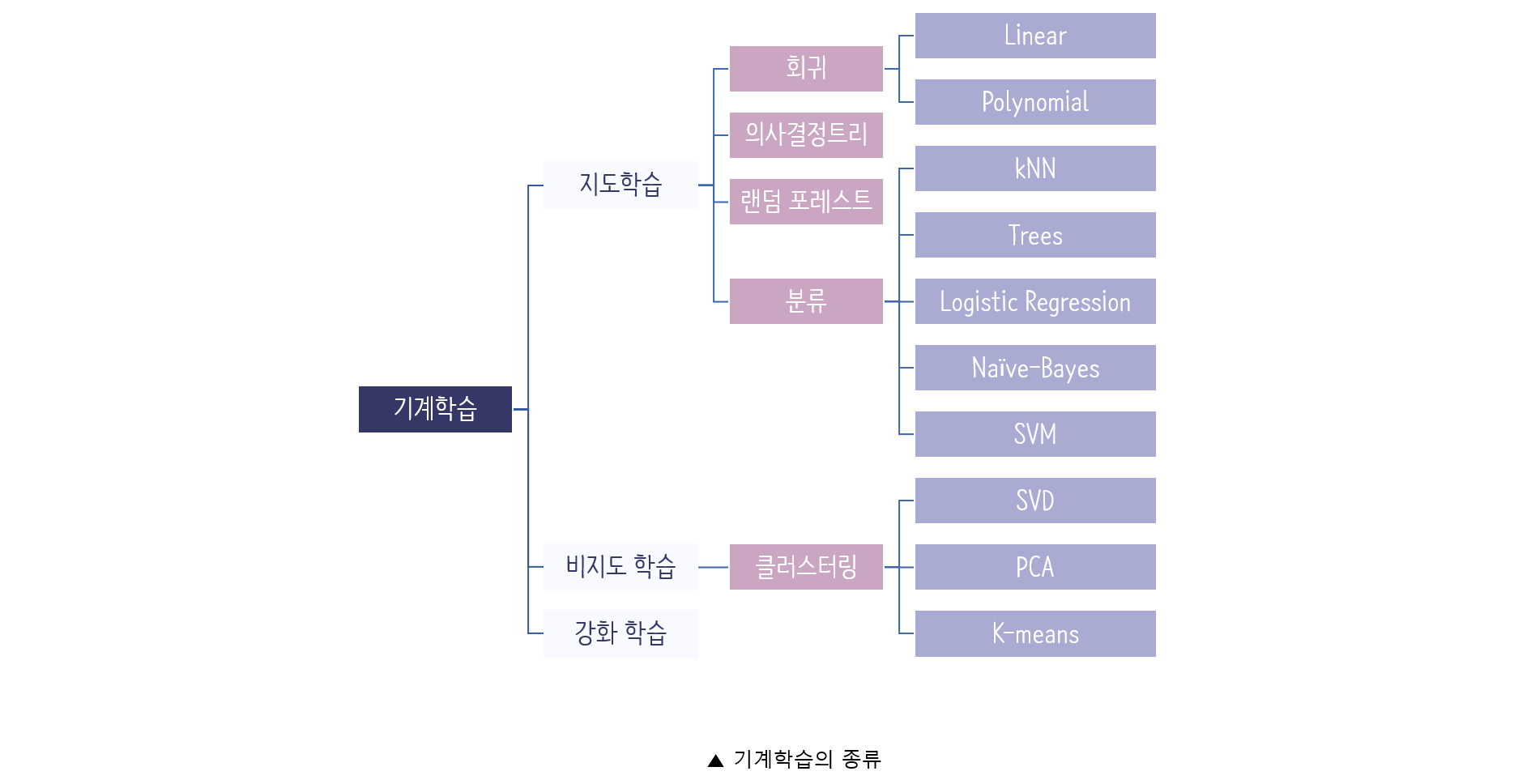
머신러닝의 종류
알고리즘 선택 시 고려 사항
알고리즘을 선택할 때에는 언제나 정확성, 학습시간, 사용 편의성 을 고려해야 합니다. 많은 경우 정확성을 최우선으로 두는 반면에 초급자는 가장 잘 알고 있는 알고리즘에 초점을 맞추는 경향이 있습니다.
데이터 세트가 제공됐을 때, ‘어떤 결과가 나올 것인지에 상관없이 어떻게 결과를 얻을것인가’를 가장 먼저 고려해야 합니다. 일부 결과를 얻었고 데이터에 익숙해진 후라면 정교한 알고리즘을 사용하는 데 시간을 더 많이 할애해야 합니다.
Leave a comment